
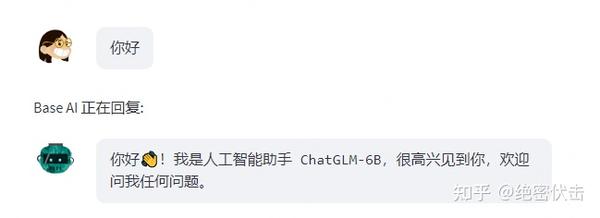
大模型微调实践:ChatGLM-6B全参数微调
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有62亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需6GB显存)。
ChatGLM-6B 是一个文本生成式对话模型,可以用于问答、闲聊等多种场景。它是由清华大学自然语言处理与社会人文计算实验室(THUNLP)开发的。
ChatGLM-6B 初具中文问答和对话功能,并支持在单张 2080Ti 上进行推理使用。具体来说,ChatGLM-6B 有如下特点:
- 充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
- 优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统 FFN 结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
- 较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
- 更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
- 人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
1. 环境搭建
基础环境配置如下:
| 配置项 | 参数 |
|---|---|
| 操作系统 | CentOS 7 |
| GPU | 8 卡 A800 80GB GPUs |
| Python | 3.10 |
| NVIDIA驱动程序版本 | 515.65.01 |
| CUDA工具包 | 11.7 |
| NCCL | nccl_2.14.3-1+cuda11.7 |
| cuDNN | 8.8.1.3_cuda11 |
备注:表中是 ChatGLM-6B 全参数微调的配置,如果是 LORA 微调,单卡 A100 40GB 就可以。
具体安装如下:
安装cuda
vim ~/.bashrc
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
安装cudnn
sudo cp cudnn-linux-x86_64-8.8.0.121_cuda11-archive/include/cudnn*.h /usr/local/cuda/include/
sudo cp cudnn-linux-x86_64-8.8.0.121_cuda11-archive/lib/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
安装pytorch
requirements.txt
protobuf>=3.19.5,<3.20.1
transformers>=4.26.1
icetk
cpm_kernels
gradio
pip3 install --user -r requirements.txt
pip install --user torch==1.10.0+cu111 torchvision==0.11.0+cu111 torchaudio==0.10.0 -f torch-1.10.0+cu111-cp39-cp39-linux_x86_64.whl -f torchvision-0.11.0+cu111-cp39-cp39-linux_x86_64.whl -f torchaudio-0.10.0+cu111-cp39-cp39-linux_x86_64.whl
2. 使用DeepSpeed数据并行进行全参数微调
下载代码:
git clone https://github.com/THUDM/ChatGLM-6B.git
cd ChatGLM-6B
cd ptuning
修改 ds_train_finetune.sh 脚本使用 DeepSpeed 进行全参数微调。
LR=1e-5
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=8 --master_port $MASTER_PORT main.py \
--deepspeed deepspeed.json \
--do_train \
--preprocessing_num_workers 32 \
--train_file AdvertiseGen/train.json \
--test_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--cache_dir cache/batch16 \
--model_name_or_path THUDM/chatglm-6b \
--output_dir ./output/adgen-chatglm-6b-ft-$LR \
--overwrite_output_dir \
--max_source_length 512 \
--max_target_length 512 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--fp16
修改 main.py 文件中的 num_train_epoch 参数(默认 num_train_epoch = 3):
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
# datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
training_args.num_train_epochs = 1
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
运行过程:
[2023-05-08 14:57:37,931] [INFO] [launch.py:229:main] WORLD INFO DICT: {'localhost': [0, 1, 2, 3, 4, 5, 6, 7]}
[2023-05-08 14:57:37,932] [INFO] [launch.py:235:main] nnodes=1, num_local_procs=8, node_rank=0
[2023-05-08 14:57:37,932] [INFO] [launch.py:246:main] global_rank_mapping=defaultdict(, {'localhost': [0, 1, 2, 3, 4, 5, 6, 7]})
[2023-05-08 14:57:37,932] [INFO] [launch.py:247:main] dist_world_size=8
[2023-05-08 14:57:37,932] [INFO] [launch.py:249:main] Setting CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
[2023-05-08 14:58:06,040] [INFO] [comm.py:586:init_distributed] Initializing TorchBackend in DeepSpeed with backend nccl
05/08/2023 14:58:07 - WARNING - __main__ - Process rank: 0, device: cuda:0, n_gpu: 1distributed training: True, 16-bits training: True
05/08/2023 14:58:07 - INFO - __main__ - Training/evaluation parameters Seq2SeqTrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=deepspeed.json,
disable_tqdm=False,
do_eval=False,
do_predict=False,
do_train=True,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=no,
fp16=True,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'fsdp_min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
generation_config=None,
generation_max_length=None,
generation_num_beams=None,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
greater_is_better=None,
group_by_length=False,
half_precision_backend=auto,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=,
ignore_data_skip=False,
include_inputs_for_metrics=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=1e-05,
length_column_name=length,
load_best_model_at_end=False,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=./output/adgen-chatglm-6b-ft-1e-5/runs/May08_14-58-06_wenliang-chatgpt2-0,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=10,
logging_strategy=steps,
lr_scheduler_type=linear,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=None,
mp_parameters=,
no_cuda=False,
num_train_epochs=1,
optim=adamw_hf,
optim_args=None,
output_dir=./output/adgen-chatglm-6b-ft-1e-5,
overwrite_output_dir=True,
past_index=-1,
per_device_eval_batch_size=1,
per_device_train_batch_size=16,
predict_with_generate=True,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=,
ray_scope=last,
remove_unused_columns=True,
report_to=['tensorboard'],
resume_from_checkpoint=None,
run_name=./output/adgen-chatglm-6b-ft-1e-5,
save_on_each_node=False,
save_safetensors=False,
save_steps=1000,
save_strategy=steps,
save_total_limit=None,
seed=42,
sharded_ddp=[],
skip_memory_metrics=True,
sortish_sampler=False,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,
xpu_backend=None,
)
GPU显存占用:
Mon May 8 19:19:51 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.108.03 Driver Version: 510.108.03 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A800-SXM... On | 00000000:0E:00.0 Off | 0 |
| N/A 63C P0 242W / 400W | 76982MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A800-SXM... On | 00000000:13:00.0 Off | 0 |
| N/A 59C P0 434W / 400W | 77174MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A800-SXM... On | 00000000:49:00.0 Off | 0 |
| N/A 56C P0 292W / 400W | 77174MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA A800-SXM... On | 00000000:4F:00.0 Off | 0 |
| N/A 71C P0 444W / 400W | 77174MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 4 NVIDIA A800-SXM... On | 00000000:91:00.0 Off | 0 |
| N/A 70C P0 449W / 400W | 77174MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 5 NVIDIA A800-SXM... On | 00000000:97:00.0 Off | 6 |
| N/A 56C P0 435W / 400W | 77172MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 6 NVIDIA A800-SXM... On | 00000000:CD:00.0 Off | 0 |
| N/A 62C P0 267W / 400W | 77174MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 7 NVIDIA A800-SXM... On | 00000000:D2:00.0 Off | 0 |
| N/A 62C P0 349W / 400W | 76980MiB / 81920MiB | 100% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
输出文件:
tree ./output/adgen-chatglm-6b-ft-1e-5
├── all_results.json
├── checkpoint-1000
│ ├── config.json
│ ├── configuration_chatglm.py
│ ├── generation_config.json
│ ├── global_step1000
│ │ ├── mp_rank_00_model_states.pt
│ │ ├── zero_pp_rank_0_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_1_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_2_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_3_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_4_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_5_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_6_mp_rank_00_optim_states.pt
│ │ └── zero_pp_rank_7_mp_rank_00_optim_states.pt
│ ├── ice_text.model
│ ├── latest
│ ├── modeling_chatglm.py
│ ├── pytorch_model-00001-of-00002.bin
│ ├── pytorch_model-00002-of-00002.bin
│ ├── pytorch_model.bin.index.json
│ ├── quantization.py
│ ├── rng_state_0.pth
│ ├── rng_state_1.pth
│ ├── rng_state_2.pth
│ ├── rng_state_3.pth
│ ├── rng_state_4.pth
│ ├── rng_state_5.pth
│ ├── rng_state_6.pth
│ ├── rng_state_7.pth
│ ├── special_tokens_map.json
│ ├── tokenization_chatglm.py
│ ├── tokenizer_config.json
│ ├── trainer_state.json
│ ├── training_args.bin
│ └── zero_to_fp32.py
├── trainer_state.json
└── train_results.json
3. 效果评估
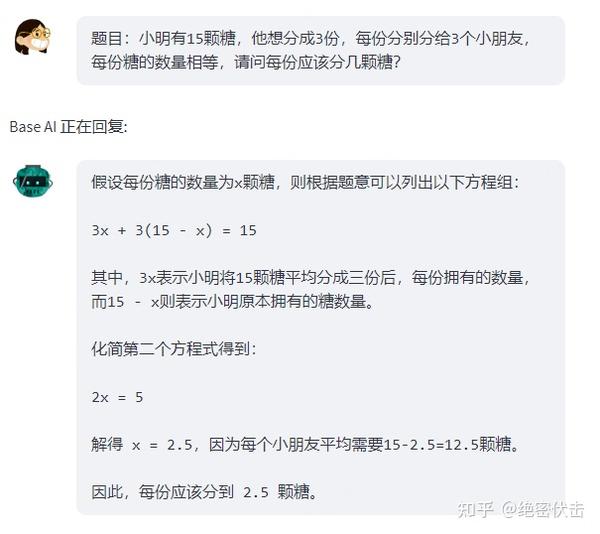
这里我们看一道简单的数学题:
题目:小明有15颗糖,他想分成3份,每份分别分给3个小朋友,每份糖的数量相等,请问每份应该分几颗糖?
ChatGLM-6B的回答如下:
假设每份糖的数量为x颗糖,则根据题意可以列出以下方程组:
3x + 3(15 - x) = 15
其中,3x表示小明将15颗糖平均分成三份后,每份拥有的数量,而15 - x则表示小明原本拥有的糖数量。
化简第二个方程式得到:
2x = 5
解得 x = 2.5,因为每个小朋友平均需要15-2.5=12.5颗糖。
因此,每份应该分到 2.5 颗糖。
这个回答明显是错误的,我们看一下微调之后的答案:

每份5颗糖没问题,但是后面一句有点多余了。
4. 训练效率
{'loss': 1.5377, 'learning_rate': 5.410753547871278e-06, 'epoch': 0.46}
46%|██████████████████████████████████████████████████████████▌ | 2309/5003 [4:22:39<4:46:55, 6.39s/it][2023-05-08 19:37:09,312] [INFO] [logging.py:96:log_dist] [Rank 0] step=2310, skipped=4, lr=[5.390765540675595e-06, 5.390765540675595e-06], mom=[(0.9, 0.999), (0.9, 0.999)]
[2023-05-08 19:37:09,512] [INFO] [timer.py:199:stop] epoch=0/micro_step=2310/global_step=2310, RunningAvgSamplesPerSec=20.097073671272955, CurrSamplesPerSec=20.104466204429873, MemAllocated=21.59GB, MaxMemAllocated=58.13GB
{'loss': 1.5591, 'learning_rate': 5.390765540675595e-06, 'epoch': 0.46}
46%|██████████████████████████████████████████████████████████▊ | 2319/5003 [4:23:43<4:45:37, 6.39s/it][2023-05-08 19:38:13,172] [INFO] [logging.py:96:log_dist] [Rank 0] step=2320, skipped=4, lr=[5.370777533479913e-06, 5.370777533479913e-06], mom=[(0.9, 0.999), (0.9, 0.999)]
[2023-05-08 19:38:13,372] [INFO] [timer.py:199:stop] epoch=0/micro_step=2320/global_step=2320, RunningAvgSamplesPerSec=20.097130490030704, CurrSamplesPerSec=20.114929649570247, MemAllocated=21.59GB, MaxMemAllocated=58.13GB
{'loss': 1.5622, 'learning_rate': 5.370777533479913e-06, 'epoch': 0.46}
47%|███████████████████████████████████████████████████████████ | 2329/5003 [4:24:47<4:44:43, 6.39s/it][2023-05-08 19:39:17,049] [INFO] [logging.py:96:log_dist] [Rank 0] step=2330, skipped=4, lr=[5.35078952628423e-06, 5.35078952628423e-06], mom=[(0.9, 0.999), (0.9, 0.999)]
[2023-05-08 19:39:17,249] [INFO] [timer.py:199:stop] epoch=0/micro_step=2330/global_step=2330, RunningAvgSamplesPerSec=20.097173576588506, CurrSamplesPerSec=20.12554582582786, MemAllocated=21.59GB, MaxMemAllocated=58.13GB
{'loss': 1.5325, 'learning_rate': 5.35078952628423e-06, 'epoch': 0.47}
47%|███████████████████████████████████████████████████████████▎ | 2339/5003 [4:25:51<4:43:35, 6.39s/it][2023-05-08 19:40:20,941] [INFO] [logging.py:96:log_dist] [Rank 0] step=2340, skipped=4, lr=[5.330801519088548e-06, 5.330801519088548e-06], mom=[(0.9, 0.999), (0.9, 0.999)]
[2023-05-08 19:40:21,141] [INFO] [timer.py:199:stop] epoch=0/micro_step=2340/global_step=2340, RunningAvgSamplesPerSec=20.097229636997643, CurrSamplesPerSec=20.10217475453911, MemAllocated=21.59GB, MaxMemAllocated=58.13GB
{'loss': 1.5225, 'learning_rate': 5.330801519088548e-06, 'epoch': 0.47}
47%|███████████████████████████████████████████████████████████▋ | 2349/5003 [4:26:55<4:42:41, 6.39s/it][2023-05-08 19:41:24,845] [INFO] [logging.py:96:log_dist] [Rank 0] step=2350, skipped=4, lr=[5.310813511892865e-06, 5.310813511892865e-06], mom=[(0.9, 0.999), (0.9, 0.999)]
[2023-05-08 19:41:25,045] [INFO] [timer.py:199:stop] epoch=0/micro_step=2350/global_step=2350, RunningAvgSamplesPerSec=20.0972429517267, CurrSamplesPerSec=20.11341719660344, MemAllocated=21.59GB, MaxMemAllocated=58.13GB
{'loss': 1.5457, 'learning_rate': 5.310813511892865e-06, 'epoch': 0.47}
47%|███████████████████████████████████████████████████████████▉ | 2359/5003 [4:27:59<4:41:31, 6.39s/it][2023-05-08 19:42:28,736] [INFO] [logging.py:96:log_dist] [Rank 0] step=2360, skipped=4, lr=[5.290825504697182e-06, 5.290825504697182e-06], mom=[(0.9, 0.999), (0.9, 0.999)]
[2023-05-08 19:42:28,936] [INFO] [timer.py:199:stop] epoch=0/micro_step=2360/global_step=2360, RunningAvgSamplesPerSec=20.097272216166992, CurrSamplesPerSec=20.09995682150088, MemAllocated=21.59GB, MaxMemAllocated=58.13GB
{'loss': 1.5437, 'learning_rate': 5.290825504697182e-06, 'epoch': 0.47}
47%|████████████████████████████████████████████████████████████ | 2365/5003 [4:28:37<4:40:51, 6.39s/it]
可以看到最后的参数:[4:28:37<4:40:51, 6.39s/it]
也就是每次迭代需要6.39秒,对于100万的数据,需要: 1000000/16/8*6.39/3600\approx13 小时。
其中16表示 batch size,8表示8张卡。100万的数据13小时可以微调完成。
-

RTX PRO 5000 Blackwell 算力加持 AIGC 全链路,宽恒科技赋能 AI 短剧工业化内容生产
短视频流量红利持续释放,AI 短剧进入工业化批量生产时代,从 AI 剧本生成、数字人形象制作、镜头视频生成、实时渲染剪辑到后期特效包装,整条内容生产线高度依赖高性能本地专业 GPU 算力支撑。NVIDIA RTX PRO 5000 Blackwell 专业显卡作为面向创意生产与本地 AIGC 推理的旗舰级工作站算力硬件,凭借 Blackwell 全新架构、最高 72GB 超大 GDDR7 显存、超强 AI 计算与视频编解码能力,成为 AI 短剧工作室、MCN 机构、影视后期团队的生产力核心硬件。广州宽恒信息科技有限公司作为英伟达专业图形卡授权合作伙伴,提供 RTX PRO 5000 正品供货、工作站整机方案搭配、AIGC 工作流优化调试一站式服务,帮助内容创作者搭建高效率、低成本的本地 AI 短剧工业化生产流水线。
넶0 2026-07-24 -
NVIDIA DGX Spark 私有化本地大模型部署落地,宽恒科技依托 Harness 工程体系构建企业私有 AI 稳定底座
数据安全合规要求持续收紧、AI 自主可控诉求不断提升的 2026 年,私有化本地部署大模型已经成为中大型企业、科研机构、涉密单位的硬性选择,公有云 API 调用模式在数据隐私、模型自主迭代、长期成本可控性上的短板日益凸显。NVIDIA DGX Spark 作为面向中小型私有化 AI 场景打造的高性能一体化算力节点,凭借 Grace Blackwell 架构、128GB 超大统一内存、单机可承载数百亿参数大模型的强悍性能,成为本地私有大模型部署的标杆硬件载体。广州宽恒信息科技有限公司基于 DGX Spark 硬件平台,结合成熟的 Harness 工程化运维体系,为客户完成从硬件交付、模型适配、集群搭建到持续迭代运维的全流程私有化大模型落地服务,打造安全、可管控、可规模化迭代的企业本地 AI 算力基座。
넶0 2026-07-24 -
企业 MR 数字化转型刚需之选,宽恒科技推荐 PICO 4 Ultra 企业版批量采购方案
2026 年混合现实 MR 技术加速从消费娱乐场景渗透至工业制造、职业教育培训、远程协同办公、建筑工装设计、虚拟展厅展示等 B 端行业,空间计算、实景三维叠加、虚实交互成为企业降本提效、创新业务模式的重要抓手。PICO 4 Ultra 企业版作为面向商用场景深度定制的 MR 一体机,凭借旗舰硬件性能、企业级设备管理系统、完善的二次开发 SDK 与安全管控能力,成为当前政企批量采购的主流机型。广州宽恒信息科技有限公司依托成熟的硬件供应链、批量采购议价优势、行业场景化部署实施能力,为广东各类企事业单位提供 PICO 4 Ultra 企业版整机采购、配套软件部署、内容定制、设备运维全链条一站式服务,是华南地区该设备批量采购值得信赖的服务商。
넶0 2026-07-24 -
英伟达官方授权代理资质加持,宽恒科技深度落地 NVIDIA AI Enterprise 企业级 AI 全栈方案
生成式人工智能进入深度产业化落地周期后,企业 AI 项目普遍面临两大核心难题:一是硬件算力与软件体系无法打通,硬件性能无法充分释放;二是开源框架零散杂乱,缺乏生产级稳定性、安全合规保障与长期技术支持,项目从实验室原型走向规模化商用断层严重。NVIDIA AI Enterprise(简称 NVAIE)作为英伟达官方推出的云原生企业级 AI 全栈软件套件,正是打通 AI 研发到生产最后一公里的核心工具,而广州宽恒信息科技有限公司作为英伟达正规授权合作伙伴,依托官方代理资质,可为华南地区各类企业提供 NVIDIA AI Enterprise 授权采购、部署实施、运维优化、技术培训一体化完整服务,助力客户搭建标准化、可管控、高可靠的企业 AI 工厂。
넶0 2026-07-24 -
算力租赁、AI 服务器租赁与大模型部署新路径,宽恒科技助力企业轻资产落地 AI 生产力
2026 年人工智能产业已经从概念普及全面迈入规模化产业落地阶段,WAIC 世界人工智能大会上行业专家达成统一共识:智能体 Agent 规模化爆发、多模态大模型迭代、长上下文深度推理正在催生指数级算力消耗,算力结构性供需失衡成为制约千行百业 AI 落地的核心瓶颈。中国信通院数据显示,本年度国内算力租赁市场全年规模有望突破 2600 亿元,AI 算力需求同比暴涨 417%,而有效供给增速仅为 128%,高端训练算力缺口接近半数,重资产自建算力机房的传统模式,早已无法适配当下 AI 快速迭代的产业节奏,算力租赁、AI 服务器弹性租赁、私有化大模型轻量化部署,成为绝大多数企业降本增效的最优解,广州宽恒信息科技有限公司(宽恒科技)凭借成熟的算力资源池、全流程部署服务能力,成为华南地区企业 AI 基建升级的可靠合作伙伴。
넶0 2026-07-24 -
RTX PRO 5000 驱动 AIGC 产业革新,宽恒科技助力 AI 短剧内容工业化生产
AIGC 内容创作全面进入工业化阶段,AI 短剧、数字人短视频、虚拟制片、广告短片需求爆发。内容工作室、影视产业园、新媒体企业需要兼顾稳定持续生产、4K 高清素材处理、多模态模型本地运行,普通消费级显卡稳定性不足、显存容量有限,难以支撑商业级量产需求。RTX PRO 5000 基于全新架构打造,配备超大 ECC 显存,兼顾专业三维图形渲染与生成式 AI 算力,成为 AI 短剧创作、本地 AIGC 工作站的核心硬件。宽恒科技提供 RTX PRO 5000 整机与工作站方案供应,面向内容创作者、影视企业输出适配 AI 短剧生产的一站式算力解决方案。
넶2 2026-07-23

