
轻松部署你自己的 Stable Diffusion 云服务
原文:Deploying Your Own Stable Diffusion Service
原作者:bozhao
译者:larme, bo jiang

以上艺术图像是使用近来最火热的 AI 数字作画模型 Stable Diffusion 根据图像下方的文本语句生成的,而 AI 生成每张图只需要数秒到数分钟。Stable Diffusion 是由 stability.ai 发布的文本到图像模型,已在近期开源。我们可以在 Stable Diffusion 的官方 Hugging Face Space 直接输入自己的文本体验。
官方展示页只是一个样例展示。如何在本地或者自己的云服务器上部署一个 Stable Diffusion,甚至能够支撑起自己生产环境的应用?下面来分享一种不需要和复杂的部署环境打交道、也不需要很多服务器知识,就能够部署一个稳定、高效的 Stable Diffusion 服务的办法。
本文参考了 https://github.com/bentoml/stable-diffusion-bentoml 的代码和示例。
本地部署
如果想直接导入预先制作好的 Stable Diffusion bento,请选择下载包含单精度(fp32)或半精度(fp16)模型的 bento。单精度模型适用于纯 CPU 环境(推理时间较长)或者显存大于 10GB 的 GPU 环境,半精度适用于显存小于 10GB 的 GPU 环境。
安装本地部署依赖
pip install "bentoml>=1.0.5" torch transformers diffusers ftfy
# 如果想在 GPU 上执行,还需要保证 CUDA、CUDNN 的环境。可以使用 conda 安装
下载打包好的 Stable Diffusion 服务(bento)
curl -O <https://s3.us-west-2.amazonaws.com/bentoml.com/stable_diffusion_bentoml/sd_fp32.bento>
# 或者使用半精度模型,占用存储更小,适合在GPU上执行 curl -O <https://s3.us-west-2.amazonaws.com/bentoml.com/stable_diffusion_bentoml/sd_fp16.bento>
# 导入 bento,模型较大,可能会花费比较长的时间
bentoml import sd_fp32.bento
启动服务
bentoml serve stable_diffusion_fp32:latest --production --port 3000
# 如果导入的是半精度版本 bentoml serve stable_diffusion_fp16:latest --production --port 3000
# 如果在 CPU 上运行 Stable Diffusion 服务,其生成时间可能超过五分钟,长于 BentoML 默认超时报错时间。这时我们可以运行以下命令,设置更长的超时报错时间后启动服务
# echo "{runners: {timeout: 900}}" > conf.yaml && (BENTOML_CONFIG=conf.yaml bentoml serve stable_diffusion_fp32:latest --production --port 3000)
就可以获得可以直接给 APP 或网页提供服务的 AI 画作 API。浏览器打开 http://127.0.0.1:3000 端口即可以看到 API 描述页面(Swagger UI)。可以点击 txt2img,直接输入 {”prompt”: “a fancy house”} 测试 API 效果。
云部署(以 EC2 为例)
由于本地计算资源有限,Stable Diffusion 模型需要很长时间才能生成高质量的图像。用云服务在线使用这个模型,能节省硬件费用,随时调用强大的云端计算资源,并使我们能够更快地获得高质量的结果。将模型托管为微服务还允许其他 AI 生成程序更容易地利用模型的功能,而同时无需烦恼在线运行 ML 模型推理的复杂性。我们可以使用 bentoctl 工具来快速创建云部署。
云部署依赖
导入 Bento
(如果在之前已经导入可以跳过这个步骤)
curl -O <https://s3.us-west-2.amazonaws.com/bentoml.com/stable_diffusion_bentoml/sd_fp32.bento>
# 或者使用半精度模型,占用存储更小,适合在 GPU 上执行 curl -O <https://s3.us-west-2.amazonaws.com/bentoml.com/stable_diffusion_bentoml/sd_fp16.bento>
# 导入 bento
bentoml import sd_fp32.bento
将 Stable Diffusion Bento 部署到 EC2
我们将使用 bentoctl 将 bento 部署到 EC2。bentoctl通过 Terraform 帮助我们将 bento 部署到多种云平台。首先我们需要安装 AWS EC2 Operator(其他云服务的 operator 请参考此列表)以生成和应用 Terraform 文件。
bentoctl operator install aws-ec2
创建一个 deployment_config.yaml 来指定 EC2 部署设置,我们也可以按照自己的需求更改这些设置,如地区、镜像。 默认的部署设置将会把 bento 部署在一台 ap-northeast-1 区的 g4dn.xlarge 实例上。 我们使用 Deep Learning AMI GPU PyTorch 1.12.0 (Ubuntu 20.04) AMI 来解决 nivida 依赖安装方面的问题.
api_version: v1
name: stable-diffusion-bentoml-tokyo
operator:
name: aws-ec2
template: terraform
spec:
region: ap-northeast-1
instance_type: g4dn.xlarge
# points to Deep Learning AMI GPU PyTorch 1.12.0 (Ubuntu 20.04) 20220913 AMI
ami_id: ami-06052cdcadbcf015d
enable_gpus: true
运行 bentoctl 命令,生成 Terraform files 和 Docker 镜像。注意:创建 Docker 镜像并推送到 AWS ECR 由于镜像体积较大,推送所需时间可能较长。
$ bentoctl generate -f deployment_config.yaml
$ bentoctl build -b stable_diffusion_fp32:latest -f deployment_config.yaml
Image pushed!
✨ generated template files.
- ./bentoctl.tfvars
- ./startup_script.sh
运行 Terraform 文件将服务部署到 AWS EC2. 然后我们可以在 EC2 控制台看到该服务。 我们也可以在浏览器里打开 EC2 实例的 IPv4 地址访问 Swagger UI.
bentoctl apply -f deployment_config.yaml
现在一个云服务就部署好了。我们可以运行以下请求来测试服务,得到以下的效果:
curl -X POST <http://127.0.0.1:3000/img2img> -H 'Content-Type: multipart/form-data' -F img="@bento.jpg" -F data="{\\"prompt\\":\\"Black and white cats.\\"}" --output output.jpg

最后,当我们不再需要 EC2 上部署的服务时,我们可以运行以下命令删除这个部署
bentoctl destroy -f deployment_config.yaml
bentoctl 也支持部署到 EC2 其他的云服务平台,参考此列表。
构建自己的服务逻辑
以上步骤都基于预先打包好的 sd_fp32.bento ,打包代码在这里 stable-diffusion-bentoml/fp32 at main · bentoml/stable-diffusion-bentoml (github.com)。如果我们想要让服务拥有自己定制的逻辑(比如用户验证)或使用其它模型,可以通过使用 BentoML 和少量的 Python 代码构建自己的 bento 包。
为什么使用 BentoML
从模型到一个服务并非一个简单的 flask 应用就可以满足需求。一个现代的适合生产环境的需要考虑可扩展性、可观测性等必要的特性。
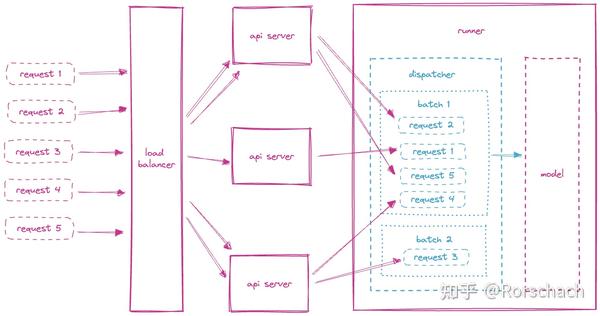
BentoML 是一个用于构建、部署和管理机器学习模型推理服务的开源框架。算法工程师和数据科学家们可以使用 BentoML 轻松地将多种 ML 框架训练好的模型打包为 API 服务,管理模型和服务的版本并将其部署到各种生产环境。BentoML 的架构通过 API Server 和 Runner 来分离请求处理和模型推理的逻辑。逻辑分离可以有效帮助相关组件的独立扩展,更有效地使用资源,以及规避 Python GIL 带来的并行限制。而 bento 是 BentoML 用来包含一个 BentoML 服务运行所需的源文件、模型文件、数据以及部署环境依赖的一种标准化格式。
准备开发环境
用 git 克隆参考的代码示例仓库,然后安装依赖库。
git clone <https://github.com/bentoml/stable-diffusion-bentoml.git> && cd stable-diffusion-bentoml
python3 -m venv venv && . venv/bin/activate
pip install -U pip
pip install -r requirements.txt
接下来我们可以选择下载 Stable Diffusion 模型或训练自己的模型。
构建自己的 Stable Diffusion bento 可以有机会去自定义预处理逻辑。如果选择自己构建,请下载单精度(fp32)或半精度(fp16)模型,单精度模型适用于纯 CPU 环境(但推理时间较长)或者显存大于 10GB 的 GPU 环境,半精度适用于显存小于 10GB 的 GPU 环境
- 下载单精度模型
cd fp32/ curl -O <https://s3.us-west-2.amazonaws.com/bentoml.com/stable_diffusion_bentoml/sd_model_v1_4.tgz> && tar zxf sd_model_v1_4.tgz -C models/ - 下载半精度模型
cd fp16/ curl -O <https://s3.us-west-2.amazonaws.com/bentoml.com/stable_diffusion_bentoml/sd_model_v1_4_fp16.tgz> && tar zxf sd_model_v1_4_fp16.tgz -C models/
构建 Stable Diffusion Bento
我们首先创建一个 BentoML 服务来把 Stable Diffusion 模型提供的接口函数转换为 RESTful API 接口。以下示例中我们会使用单精度(fp32)模型进行推理,通过 service.py 模块将服务与业务逻辑联系在一起。我们可以使用 @svc.api 装饰器装饰模型的接口函数,BentoML 将会把它们转换成 API 接口。此外,我们可以在参数中指定 API 的 input 和 output类型。例如,txt2img 接口接受 JSON 类型输入并返回 Image 类型输出,而 img2img 接口接受 一个 Image 类型以及一个 JSON 类型作为输入,并返回一个 Image 类型作为输出。我们可以在这里加入自己的请求处理逻辑。
@svc.api(input=JSON(), output=Image())
def txt2img(input_data):
return stable_diffusion_runner.txt2img.run(input_data)
@svc.api(input=Multipart(img=Image(), data=JSON()), output=Image())
def img2img(img, data):
return stable_diffusion_runner.img2img.run(img, data)
StableDiffusionRunnable 的代码是我们模型推理的核心逻辑,它负责调用 txt2img_pipe 和 img2img_pipe 这两个模型接口函数以及处理吊用的各种参数。StableDiffusionRunnable 会启动一个自定义的 Runner 实例。该实例负责在我们的 RESTful API 后运行模型的推理逻辑并返回推理结果。BentoML 内置对各种主流的机器学习框架的支持,大部分情况下开发者不需要自己写 Runnable 相关代码
stable_diffusion_runner = bentoml.Runner(StableDiffusionRunnable, name='stable_diffusion_runner', max_batch_size=10)
接下来,运行以下命令以启动 BentoML 服务进行测试。使用 CPU 在本地运行 Stable Diffusion 模型推理耗时较多,每个请求大约需要 5 分钟甚至更长才能完成。
BENTOML_CONFIG=configuration.yaml bentoml serve service:svc --production
我们可以运行以下的脚本来测试 /txt2img 和 /img2img 这两个接口,生成结果会被保存为 output.jpg
curl -X POST <http://127.0.0.1:3000/txt2img> -H 'Content-Type: application/json' -d "{\\"prompt\\":\\"View of a cyberpunk city\\"}" --output output.jpg
curl -X POST <http://127.0.0.1:3000/img2img> -H 'Content-Type: multipart/form-data' -F img="@input.jpg" -F data="{\\"prompt\\":\\"View of a cyberpunk city\\"}" --output output.jpg
测试完毕后,我们可以把当前的服务打包为一个 bento。通过创建一个 bentofile.yaml 文件(更多关于此文件格式的信息请参照这里), 我们可以让 BentoML 得知它需要构建 bento 所需的全部信息:
service: "service.py:svc"
include:
- "service.py"
- "requirements.txt"
- "models/v1_4"
- "configuration.yaml"
python:
packages:
- torch
- transformers
- diffusers
- ftfy
docker:
distro: debian
cuda_version: "11.6.2"
env:
BENTOML_CONFIG: "configuration.yaml"
运行下面的命令我们就可以构建我们的 Stable Diffusion bento
bentoml build
# 查看现有的所有 bento
bentoml list
总结
在本文中,我们使用 BentoML 为 Stable Diffusion 构建了一个可以轻松部署在各种生产环境的服务,并将其部署到 AWS EC2。在 AWS EC2 上部署该服务使我们能够在更强大的硬件上运行 Stable Diffusion 模型,生成具有低延迟的图像。同时服务也可以随时扩展到多台机器。如果你喜欢这篇文章,可以加入 BentoML 的 Slack 社区,结识更多志同道合的朋友。
本文使用到的链接:
-

RTX PRO 5000 Blackwell:专业桌面算力巅峰,英伟达显卡总代宽恒科技赋能产业 AI 升级
2026 年生成式 AI 与专业创意产业迎来算力升级浪潮,本地 AI 开发、多模态内容生成、工业 3D 设计、影视渲染等场景对桌面端高性能专业显卡需求激增。NVIDIA RTX PRO 5000 Blackwell 作为英伟达最新一代专业桌面 GPU,基于 Blackwell 架构打造,融合 AI 算力、图形渲染与专业稳定性,成为专业人士与中小企业的首选算力设备。宽恒科技作为英伟达显卡核心总代与 NPN Elite 精英级代理,深耕专业显卡领域,依托正品保障、优先供货、原厂技术支持与全栈服务体系,为企业与专业用户提供 RTX PRO 5000 Blackwell 全流程解决方案,赋能本地 AI 开发与专业创意工作流升级,推动产业数字化创新。
넶0 2026-05-22 -
桌面 AI 超级计算机,重构本地大模型开发新范式,宽恒科技赋能个人与中小企业 AI 创新
2026 年生成式 AI 进入 “本地部署” 黄金时代,大模型从云端向桌面端下沉,个人开发者、中小企业对本地高性能 AI 算力需求激增。传统 AI 服务器体积庞大、价格高昂,云端算力存在数据隐私风险与网络延迟问题,难以匹配本地开发需求。NVIDIA DGX Spark 作为全球首款桌面级 AI 超级计算机,基于 Grace Blackwell 架构打造,将超算级算力浓缩至桌面尺寸,支持本地运行千亿参数大模型,彻底打破本地大模型开发的算力瓶颈NVIDIA 英伟达。宽恒科技紧跟 AI 算力下沉趋势,依托英伟达官方合作资源,深耕 DGX Spark 技术服务领域,为个人开发者、中小企业提供产品供应、技术支持与定制化解决方案,赋能本地 AI 创新,推动普惠 AI 发展。
넶0 2026-05-22 -
HTC VIVE Focus Vision 与 VIVE Cosmos 技术解析:XR 技术革新,宽恒科技赋能行业沉浸式应用
2026 年 XR(扩展现实)技术正从消费级娱乐向企业级应用深度渗透,成为空间计算、数字孪生、远程协作、工业培训等领域的核心支撑。HTC VIVE 作为全球 XR 技术领军品牌,凭借多年技术积累与创新能力,推出 VIVE Focus Vision 与 VIVE Cosmos 两款标杆级产品,分别定位高端企业级 XR 一体机与模块化 VR 系统,覆盖不同应用场景,引领 XR 技术发展方向。
넶0 2026-05-22 -
英伟达授权生态全解析:NPN、NVAIE 与 Elite 精英代理,宽恒科技引领产业算力服务升级
2026 年 AI 产业进入规模化落地关键期,英伟达作为全球算力基础设施龙头,其授权体系已成为连接技术、产品与市场的核心纽带。从 NPN 合作伙伴网络到 Elite 精英级别代理,从 NVAIE 认证到 NVIDIA AI Enterprise 软件授权,从数据中心解决方案授权到显卡总代体系,英伟达构建了层级清晰、权责明确、技术赋能的生态体系。宽恒科技深耕英伟达生态多年,凭借技术实力、服务能力与行业资源,成为英伟达授权体系核心参与者,依托全栈授权资质,为企业提供正品保障、原厂技术支持与定制化解决方案,推动英伟达技术在各行业深度应用,助力中国 AI 产业突破算力瓶颈、实现高效升级。
넶0 2026-05-22 -
算力租赁、GPU 集群与 AI 服务器:英伟达生态驱动产业算力升级,宽恒科技赋能企业 AI 转型
在生成式 AI 与大模型爆发的 2026 年,算力已成为数字经济的核心生产力。从千亿参数大模型训练到多模态 AI 推理,从自动驾驶仿真到医疗基因测序,算力需求呈指数级增长,传统算力模式难以匹配产业发展节奏。算力租赁、GPU 集群与 AI 服务器构成的新型算力体系,正成为企业突破算力瓶颈的关键路径,而英伟达凭借完整技术生态主导产业方向,宽恒科技深耕算力服务领域,依托英伟达技术与资源优势,为企业提供全栈算力解决方案,推动 AI 产业高效落地与创新升级。
넶0 2026-05-22 -
RTX PRO 5000、英伟达 pro 5000、pro 5000 blackwell、英伟达显卡总代 —— 宽恒科技赋能专业桌面算力新巅峰
2026 年专业可视化与本地 AI 开发需求爆发,RTX PRO 5000 Blackwell 作为英伟达推出的旗舰级专业显卡,以 Blackwell 架构、超大显存与强劲算力,成为专业设计与本地 AI 开发的核心硬件,宽恒科技作为英伟达显卡总代,依托顶级资质与供应链优势,为用户提供正品保障与全栈服务。
넶2 2026-05-21

